获取淘宝商品原价、券后价的区别在哪里?难度以及解决办法
在电商数据采集、比价系统、商品信息监控、价格波动分析等开发场景中,开发者经常需要提取淘宝商品的原价与券后实付价。很多初学者在开发时会发现:页面展示的原价很好抓取,但是券后价、优惠到手价经常获取不准、数据错乱、解析为空,甚至接口返回数值和用户实际下单价格不一致。
本文从字段来源、平台底层逻辑、前端渲染差异、风控加密原因,详细讲解原价与券后价的本质区别,分析各自采集难度差异,并给出对应的技术解决思路与通用实现方案,同时标注合规边界与开发避坑要点。
一、原价与券后价的本质区别
1. 字段定义区别
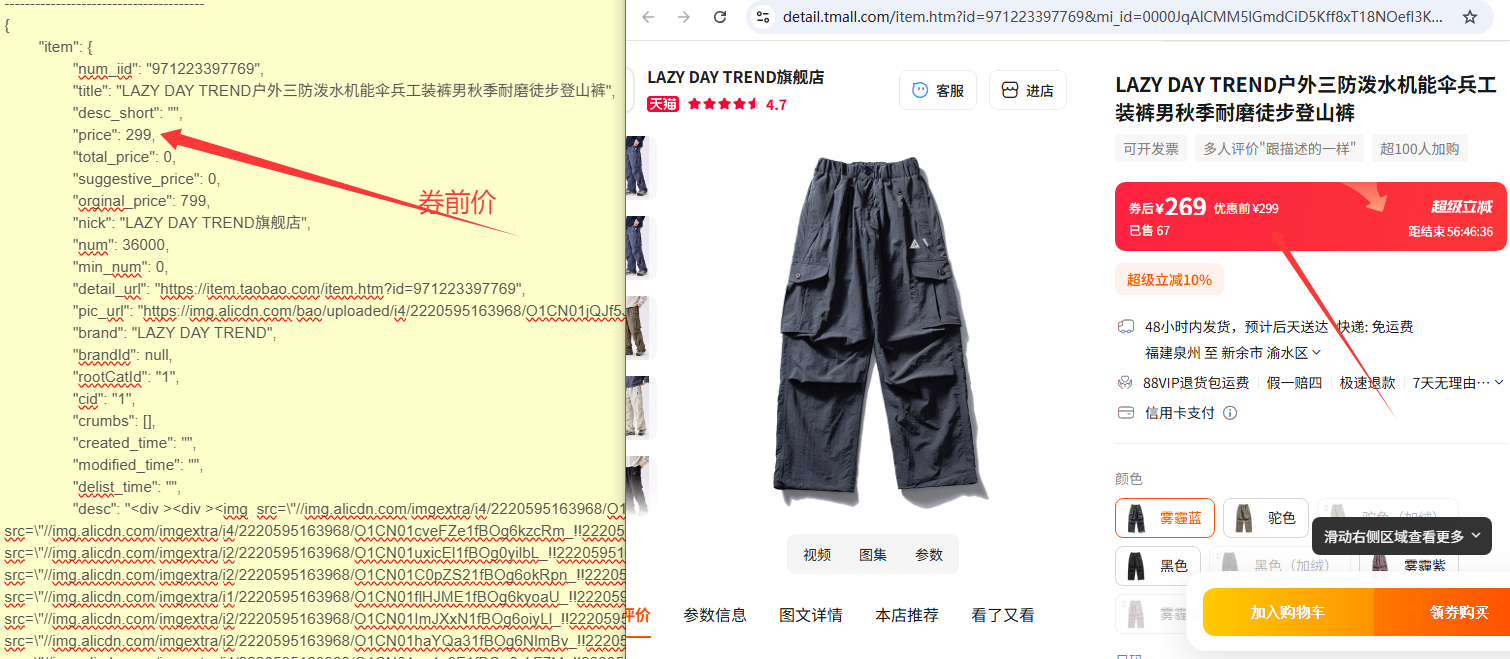
商品原价(划线价、日常售价)商家后台设置的基础标价,属于商品固定基础属性,不参与平台优惠、店铺优惠券、满减活动计算。展示位置:商品标题下方原始标价、页面划线价格。数据特点:固定值、不随用户账号变化、不随活动时效频繁变动。
券后价(到手价、优惠实付价)平台综合计算后的最终支付价格,计算公式:券后价=原价−店铺优惠券−跨店满减−平台补贴−红包抵扣数据特点:动态计算值,会随优惠券有效期、用户账号、活动时段、满减门槛实时变化。
2. 数据来源区别
原价:直接存储在商品基础信息字段中,属于商品静态元数据;
券后价:由淘宝前端 JS 引擎实时运算得出,不属于原始商品数据,页面源码中不会直接明文展示。
3. 用户展示区别
原价:所有用户看到的数值统一;
券后价:不同账号、不同地区、不同时间段领取优惠券不同,到手价可能不一样。
二、两者获取难度对比
1. 获取原价:难度极低
价格直接写在 HTML 静态源码内;
不受 JS 加密、签名、动态渲染影响;
普通 requests 请求即可直接解析;
页面结构长期稳定,爬虫代码几乎不用频繁维护;
无账号依赖、无需 Cookie、无需登录态。
2. 获取券后价:难度极高,也是开发痛点
价格后端加密返回,HTML 源码不直接暴露明文到手价;
依赖前端 JS 动态计算逻辑,原始页面无法直接提取;
绑定用户会话 Cookie、优惠券池、活动配置;
平台频繁更新优惠算法、参数加密规则;
无有效登录态时,平台不返回真实优惠价格;
满减叠加逻辑复杂,自行逆向计算极易出错。
三、为什么券后价很难采集?底层原因拆解
优惠数据接口独立淘宝将商品基础信息、优惠券信息、满减规则拆分为多个独立接口请求,并非整合在商品主页接口中,单纯爬详情页拿不到优惠数据。
JS 实时运算机制浏览器加载完所有资源后,脚本内部做减法、门槛判断、叠加校验,最终渲染出券后价,属于运行时数据,非源码内嵌数据。
风控校验严格平台对优惠链路做签名校验,无合法 Cookie、设备环境、请求频次异常,直接屏蔽优惠接口,返回空数据或默认原价。
活动动态变更频繁日常活动、大促活动、限时券、秒杀价切换快,接口参数经常迭代,旧解析规则快速失效。
账号差异化数据新用户券、老用户券、限购券、隐藏券不属于公开通用数据,无对应会话无法获取真实到手价。
四、常规解决办法与实现方案
结合开发现状,分为爬虫解析方案、官方接口方案两类技术路线,附带原理与可运行 Python 示例,全程仅用于技术学习研究。
方案 1:静态爬虫提取原价(简单稳定版)
适合仅需要基础标价,无需优惠价格的场景。
方案 2:携带 Cookie 请求优惠接口获取券后价
券后价必须请求平台优惠专用接口,同时携带有效浏览器 Cookie,平台才会返回优惠信息,再结合原价做价格还原。核心思路:
携带正常浏览器 Cookie 访问;
请求商品优惠信息独立接口;
解析优惠券面额、满减门槛;
程序内按照平台规则计算券后价。
Python 简易封装示例:
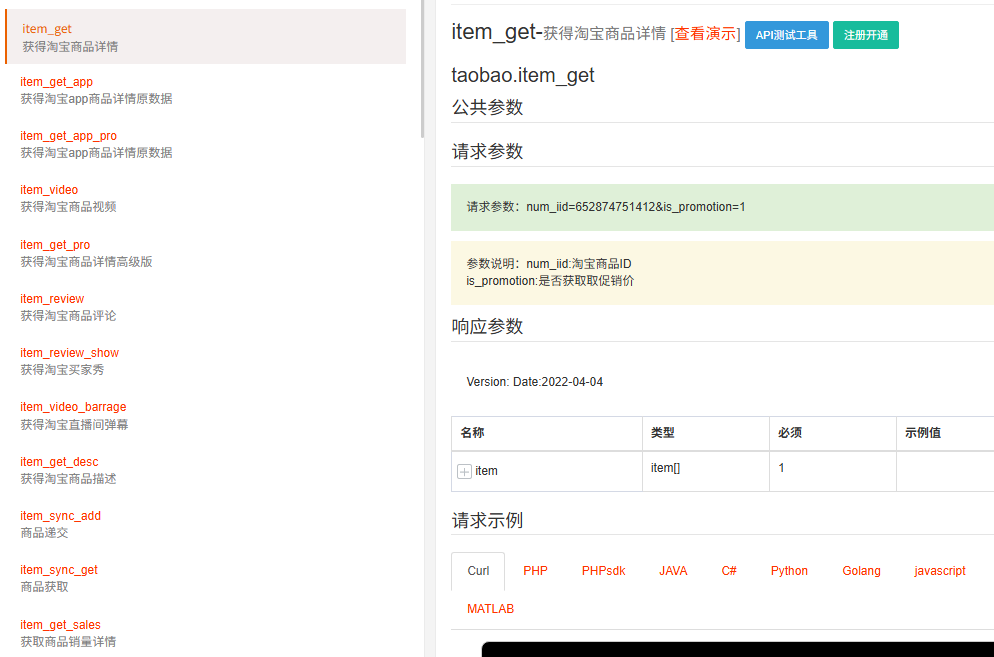
方案 3:淘宝开放平台官方 API 方案(合规最优解)
爬虫方式始终存在页面改版、风控封禁、Cookie 过期问题,企业级稳定项目优先使用官方开放接口。
平台接口直接返回结构化字段:原价、优惠价、券面额、活动价;
无需逆向 JS、无需解析页面、无需维护 Cookie;
数据官方权威,不存在计算偏差;
不受前端页面改版影响,稳定性最高;
完全合规,无反爬拦截风险。
官方接口核心字段说明:
price:商品原价promotion_price:活动售价coupon_info:优惠券相关信息final_price:官方核算到手价
五、开发常见踩坑总结
直接解析 HTML 拿券后价永远不准页面展示的券后价是 JS 渲染结果,源码无明文,盲目 xpath、bs4 解析只会拿到空值。
无 Cookie 请求一律拿不到优惠数据淘宝优惠体系绑定用户会话,匿名请求只会返回原价,屏蔽所有券信息。
自行叠加计算容易出错跨店满减、品类券、店铺券、红包优先级规则复杂,手动计算和用户真实下单价经常不一致。
Cookie 极易过期失效浏览器登录态定期失效,爬虫程序会突然全部返回原价,需要定期更新会话。
大促期间算法变动频繁618、双 11 活动期间平台会临时修改优惠链路,原有接口直接失效。
六、项目选型最终总结
仅需商品原价使用普通静态爬虫即可,开发简单、稳定、无需 Cookie、维护成本极低。
需要精准券后实付价不建议深度逆向前端 JS 加密算法,优先对接淘宝开放平台官方 API,数据权威稳定且合规。
个人学习场景仅做少量数据测试,控制请求频率,不批量高频采集,遵守平台服务协议与网络合规要求。
商用比价系统、长期价格监控项目统一采用官方接口方案,规避风控封禁、数据错乱、Cookie 维护等一系列问题,是工程化落地的最优解。
电商价格数据开发的关键点在于区分静态商品属性与动态优惠属性,原价属于固定数据容易获取,券后价属于平台动态运算数据,难点集中在会话校验、接口加密、优惠链路解析上,合理选择技术方案可以大幅降低开发与后期维护成本。